Fixed Income Investing. Reimagined.
bondIT combines innovative portfolio construction technology with AI-driven credit analytics to bring efficiency, performance and scale to your investment processes.
Book a DemobondIT applies cutting-edge AI and other advanced technology to fixed income markets. We empower asset & wealth managers with a wide range of customisable tools to build, manage and monitor their portfolios.
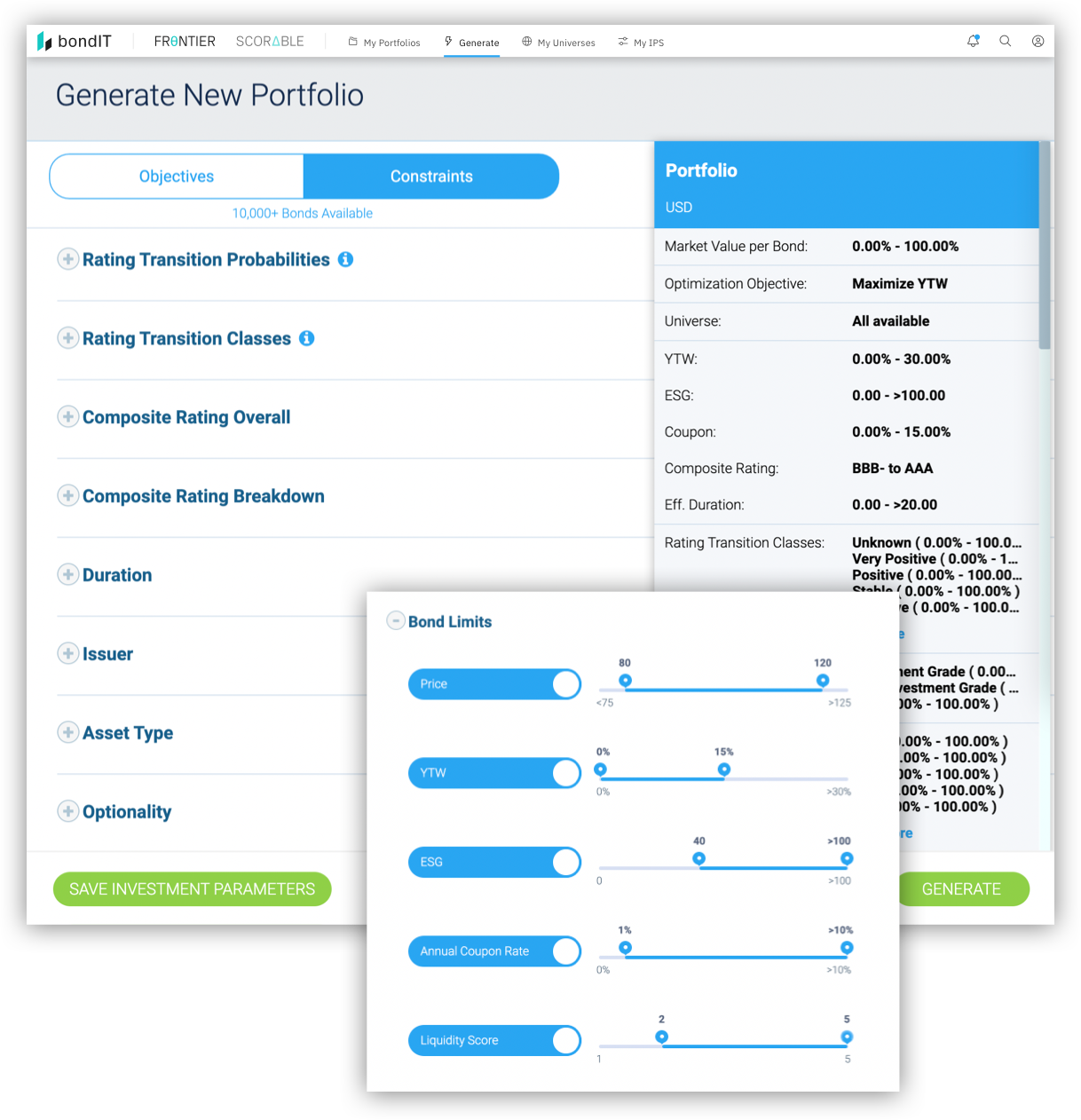
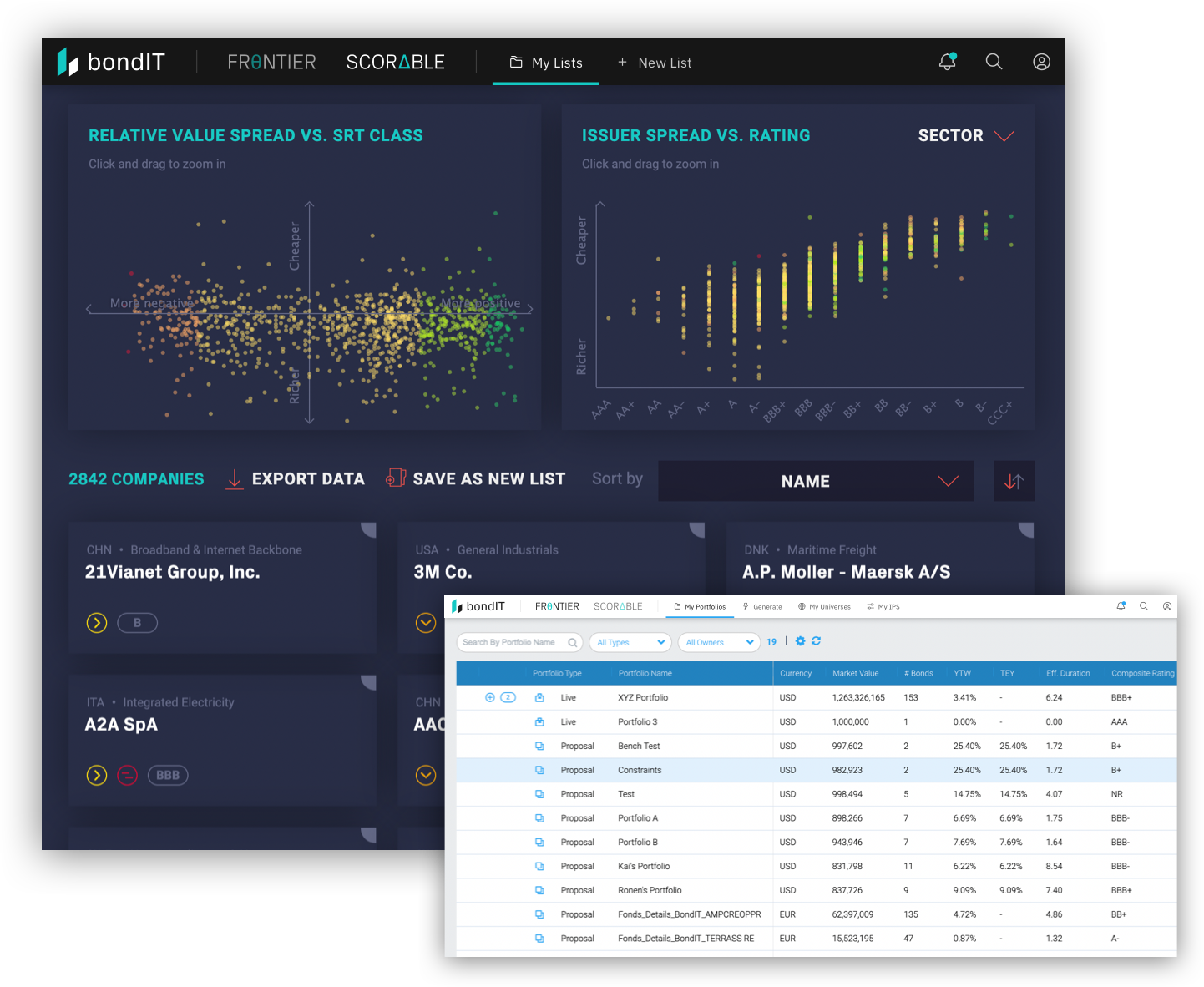
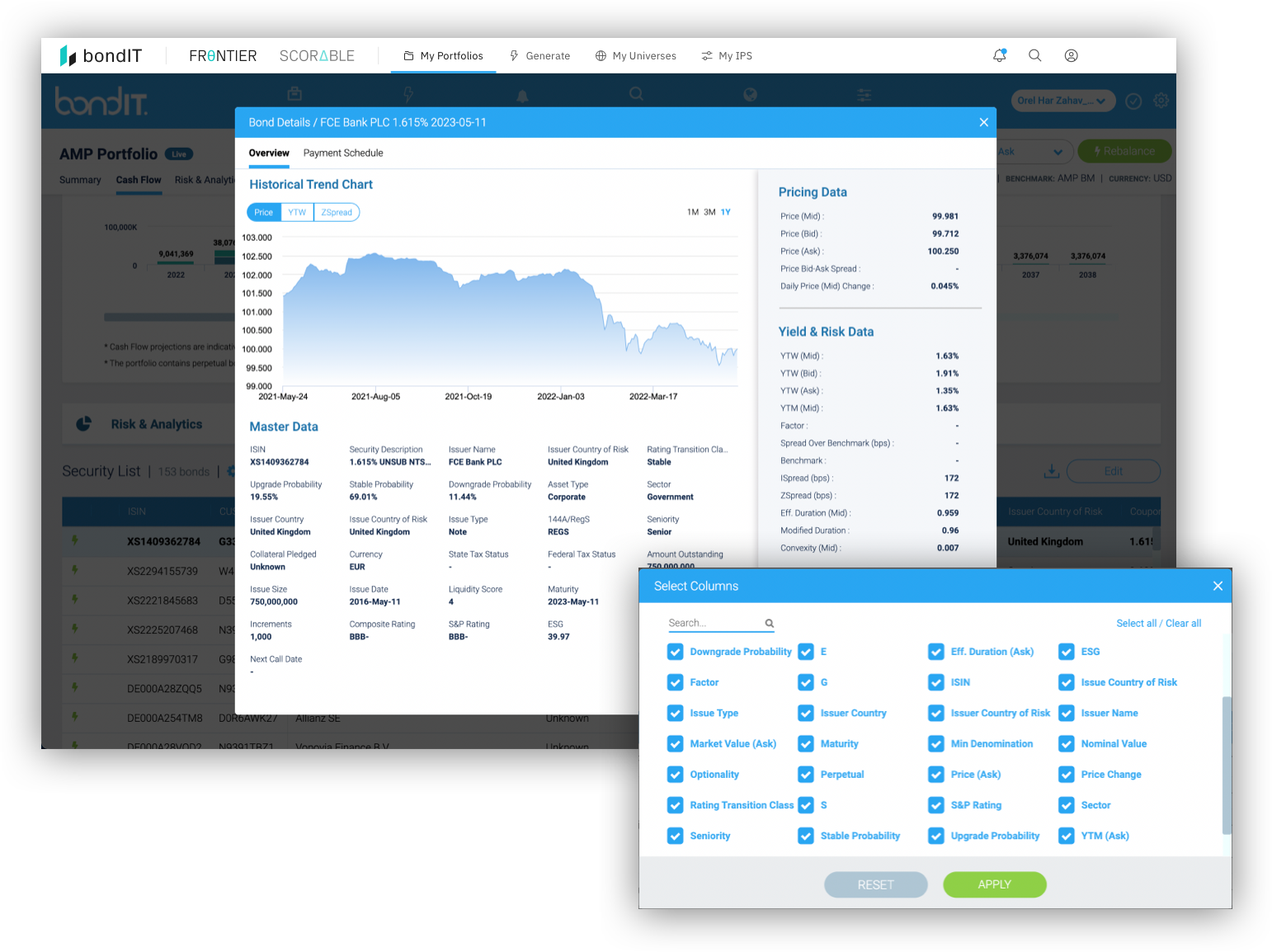
Efficiently build, optimize and analyze fixed income portfolios with FRONTIER, bondIT’s innovative Portfolio Construction technology. What previously took days can now be done in minutes with greater accuracy based on data-driven analytics.
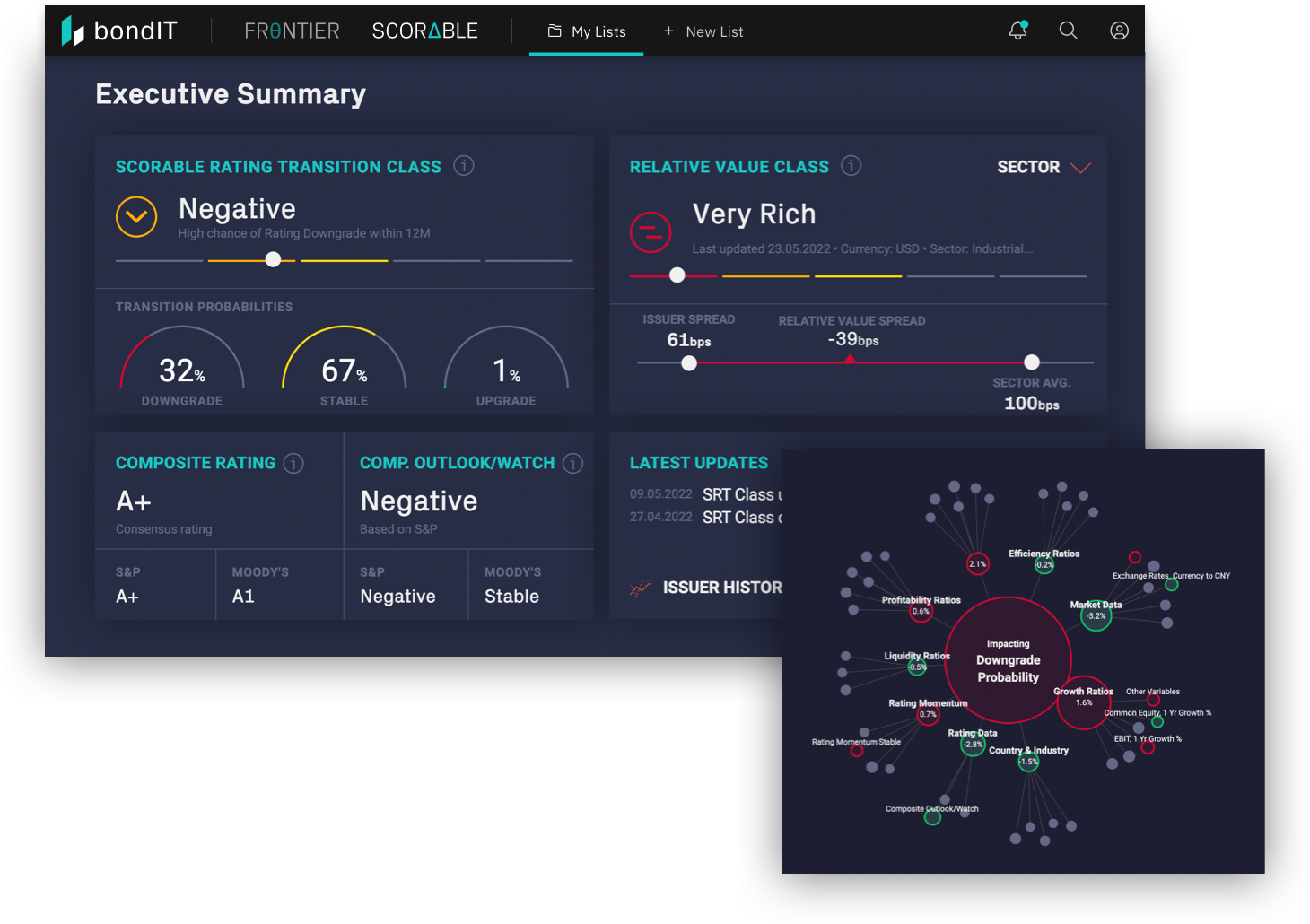
bondIT’s SCORABLE turns data into performance with AI-driven predictive Credit Analytics. Our Explainable-AI (XAI) analyses more than 250 data variables and 350 Gigabytes every day, to determine issuer-specific credit risk, helping our clients identify investment opportunities ahead of the market. Unlike “black box” models, our XAI allows users to understand the rationale behind our model’s results to ensure transparency and understanding.
bondIT helps clients automate crucial parts of their Fixed Income investment processes -- so they can manage more accounts and strategies, improve outcomes and deliver bespoke solutions with the highest degrees of efficiency.
Future-proof your investments and maximise ESG scores across your portfolios at the click of a button. bondIT's data-agnostic technology lets you incorporate the widest range of ESG factors available.
CIO, Ampega Asset Management
Partner & Portfolio Manager at Sarson Strover
Head of Business Management at MEAG